Rapid Decisions – Automating Decision Processes
Businesses make a myriad of decisions every day. Put these decisions into effect as quickly as possible. A fast response with a good decision is usually better than a slow response with an ideal decision. When time to respond is critical or expected frequency of change is high, operational decisions should be automated.
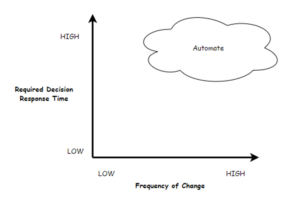
Business logic is the broad category term covering the spectrum of business processes (AKA workflow), data processes, and decision processes. The most volatile area is around decision processes; and automating that area is the focus of this post.
What tactics or tools can be applied to decision processes? A company can:
- create a software program
- use a rules engine
- use a decision engine
- general purpose
- structured
- build and deploy a model with a bit of tacked on decisioning
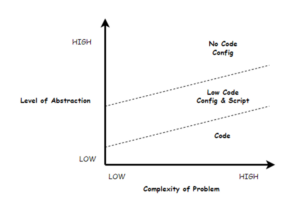
From Code to Low Code to No Code
Implementing a software program is always an option. However, in a typical business environment, that means getting into a queue to wait for IT resources to become available. The programming process also implies a software development life cycle (whether agile or not) that includes an elaboration of requirements, interpretation of those requirements into working code, testing, fixing, more verification, and finally deployment.
You may get an initial implementation deployed if requirements are well-defined, the development project is well-managed, and IT resources are available. However, the normal life cycle of decisioning is that future frequent changes must be part of the plan. Will each decision change require another software change request?
Instead of coding by a software developer, you can explore tools that offer ‘No Code’ or ‘Low Code’ capabilities. Although these terms originated in characterising how to build an application via configuration with a graphical user interface rather than with software code, the concept of putting a non-programmer in charge of implementation is useful when thinking about either rules or decision engines.
Early artificial intelligence research contrasted approaches for representing knowledge across the poles of declarative vs procedural. Configuration is closer to the declarative pole while programming gets deeper into procedure.
Programming is about solving problems through the design and implementation of data structures and processes. ‘No Code’ first of all presumes “no programmer” (programmers have already done the work that makes minimal code feasible), which implies a business user can configure rather than labour over the details of implementation. ‘No code’ is configuring through direct manipulation at the UI rather than typing in text.
Moving deeper down the dimension of problem abstraction, ‘Low Code’ offers the business user some alternative ways to represent business logic, for example, through scripting or writing a bit of code.
Rules to Decision Engines
Representation of knowledge as rules is part of the historical evolution of AI, an early effort to represent knowledge declaratively rather than procedurally. A Rules Engine that supports Inference expresses a collection of rules in a declarative fashion. Inference mechanisms and algorithms (like Rete or Phreak) will determine how and when the rules are fired once execution is triggered. Modern Rules Engines will also allow you to explicitly sequence the firing of the rules dispensing with the need for inferencing.
Historically, the Decision Engine emerged as a response to the need to represent business logic in a larger variety of useful forms beyond just rules. A decision engine may be general purpose, for example, supporting Decision Model and Notation (DMN) as an executable decision model specification language.
A decision engine may also be delivered already configured with an underlying framework or template of decision process flows. These are preconfigured based on the domain knowledge of experts in a particular problem domain. A template decision process offers a kind of business logic bauplan as a leveraged starting place for the problems to which a decision engine is targeted. Not surprisingly, it turns out that there is a lot of commonality in the broad outlines of various decision processes.
What then are the building block elements of such a template decision process? A business decision implemented in an operational system will require some or all of the following decisioning elements broadly following this sequence:
- Receive input data about an application, an account, or an event, for example
- Tap into and retrieve data from other data sources (for example, account history, credit bureau, look up tables, etc.)
- Calculate additional variables based on the received (input) or retrieved data and on other computed variables
- Apply rules to sort out the nature of the decision request or to assure that government or company policies are enforced
- Segment your accounts, applications, or other records into portfolios, products, experimental groups and/or request types
- For each segment, apply additional calculations or rules
- Make predictions about future behaviour, performance, or value (e.g. risk, response, profit, delinquency, recoveries etc.)
- Apply a decision scheme using all of the variables collected or created so far to further divide your accounts into smaller groups and then setting unique treatments or action plans for each
- Package up the decision results and returning them to the operational system or the people that can complete the execution of the decision and application of the treatment
A good decision engine provides you with a visible decision process exposing the working organs of:
- Calculation
- Policy
- Segmentation
- Prediction
- Decision
The overall process is instrumented with key decision points that you can instantly view, modify, test, and re-deploy back into your organisation’s operational environment.
‘Low Code’ means that a user does not have to delve into the details. Instead, the user configures around the critical and visible decision points using a variety of decision engine configurable components:
- Decision or segmentation trees
- Actions and action plans
- Rules
- Rulesets
- Decision matrices
- External service calls for data or for service
- Decision sub-processes
- Decision branches
- Score or model prediction computations
- Relatively simple and contained scripts for implementing business logic or calculations
The Modeller’s Dilemma
So, what about models? What about machine learning?
A predictive model computes an extremely powerful and useful additional data source for use within decisioning and offers a glimpse of a possible (or probable) future. The results of a predictive model are normally a probability or a score, for example, a prediction of credit risk. Then, once the credit score is derived, it can be used (for example in a decision matrix) to assign different credit terms for each band of risk.
Here is an example of hierarchical decision processes leading to the execution of a predictive model (or computation of a Score):
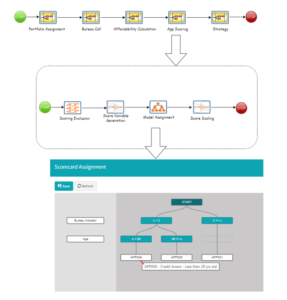
At the leaf nodes of a model assignment tree, a model (or scorecard) can be invoked. This invocation can be to a proprietary scorecard execution or perhaps an outbound call to an external service. Here is a simple abbreviated example of what such might look like:
Script calling an external service within the scoring decision process step
Deployment of the model runtime implementation has proven to be a challenge with an evolving range of choices:
- coding an implementation of the model execution
- exporting a representation of a model into an executable notation
- deploying the model in a container that can be referenced via a REST API endpoint
Coding introduces the usual hazards of interpretation of specification, testing, and likely delays. There are some model representation notations such as Predictive Model Markup Language (PMML) or Portable Format for Analytics (PFA); however, these are not universally available; and there are not always performant engines for executing these models from these notations.
Over the last several years a new and flexible option has emerged: model deployment can be achieved by packaging the model and its dependencies (including the runtime modules required to execute the model) into a container and then using scalable computing environments such as Kubernetes. Inside the container (where all of the dependencies are taken care of) is typically a simple program that is part of servicing the model execution requests (normally with a REST API front end). Having a model accessible from a decision process is a powerful option.
With the development of this option, a new temptation has emerged. In the program that is responsible for servicing a model execution request, it is also feasible to tack on and implement via code some modest amount of decisioning. Instead of having the model invoked for a prediction, an endpoint might be invoked for prediction AND decision. For expediency or for testing purposes, this is an interesting but ultimately doomed trend. This ad hoc approach will break down when things get just a little more complicated:
- different models are developed for different segments of population
- different decision strategies are to be applied for different portfolios or for A/B testing
- the degree of decision strategy process complexity is high such that managing a coded implementation of decisions becomes burdensome
The details of the decision are also not visible and business users cannot easily access the rules. It is acceptable for a model to essentially be a predictive black box; however, the business users (e.g., credit risk analysts) need to be able to see and to quickly change the decisions and, even more importantly, be able to run A/B tests.
Summary
You do not need a decision engine to help you decide to adopt a decision engine. It will help automate a wide class of business logic and decisions challenges. A good decision engine hits a sweet spot of business user configurability with visual and familiar decision elements, easy integration with predictive models, scalability, and easy deployment. The key to choosing what type is to avoid re-inventing the wheel and use configured and easy to change structures when dealing with known use cases.
About the Author
Stephen John Leonard is the founder of ADEPT Decisions and has held a wide range of roles in the banking and credit risk industry since 1985.
About ADEPT Decisions
We disrupt the status quo in the lending industry by providing lenders with customer decisioning, credit risk consulting and advanced analytics to level the playing field, promote financial inclusion and support a new generation of financial products.