Why is end-to-end decisioning so important?
Most lenders are now placing a greater emphasis and budgets on advanced analytics platforms and resources. This makes sense, as all market have become increasingly competitive, and so the ability to fine tune and rework predictive models is an important part of retaining competitive advantage.
The most frequently heard buzzwords in the credit industry over the last few years have been ‘machine learning’ and ‘AI’. The focus has been on using these tools to enhance and iterate on predictive models, to fine tune selection and offer criteria. Machine learning models are retrained on a regular basis, constantly looking to squeeze that extra gramme of performance out of the models.
In the rush to build new and better predictive models, one factor is often overlooked. In a modern credit granting business, the ability to automate complex decisioning algorithms is as important to the success of the business as the data analytics that informs the decisions to be made.
It is critical that the credit risk management team has both the ability to implement and maintain complex decisioning criteria and the flexibility to monitor and update the decisioning requirements by means of structured and easy to use tools that ensure the integrity of the decisioning process.
It is the combination of both great models and great strategies that will take the business forward and achieve a competitive advantage.
The continual growth in product offerings, channels of interaction and data sources for assessment mean that simple decisioning based on policy rules and a single score cut-off is no longer sufficient. Modern decisioning must allow for multiple scores to be calculated per applicant/account, all sourced from different data assets. These scoring outcomes should be combined into aligned customer segments for treatment, so that consistent, understandable, and automated actions can be taken.
All of this needs to be available in a framework that supports side-by-side champion/challenger testing, enabling business users to continually evaluate the success of the strategies that are applied. This will ensure the best action is applied to the customer base and maximise profitability for the business.
This is particularly true in the world of mobile and micro lending. In these industries, the customer segments that we are dealing with are often unbanked, and have no traditional credit footprint (i.e., credit bureau record). The value of credit products being offered is low, but the volume of applicants is extremely high.
Because of the high volume/low value account base, all interactions need to be as streamlined and cost-effective as possible. Manual credit assessment is simply not feasible in this market. All decisioning needs to be both automated (to reduce costs) and rigorously controlled (as a small error in a strategy could affect a massive volume of customers). The use of digital technology rather than manual channels to communicate and resolve queries is also key.
Decisioning sits at the heart of everything that a credit granting organisation does. It manages what products to offer to consumers and when to offer them. It assesses those consumers as individuals to determine what value of credit should be offered, and the pricing terms to be applied. It tracks the ongoing performance of the approved consumer, to reassess the terms and conditions granted, proactively increasing limits, and offering additional supplemental or complementary products to the customer at the right time.
Finally, should the customer default on their credit commitments, decisioning provides a path to rehabilitation for the customer, and failing that, assists the organisation to minimise credit losses from the customer.
Key decisioning points within the credit life cycle are illustrated below:
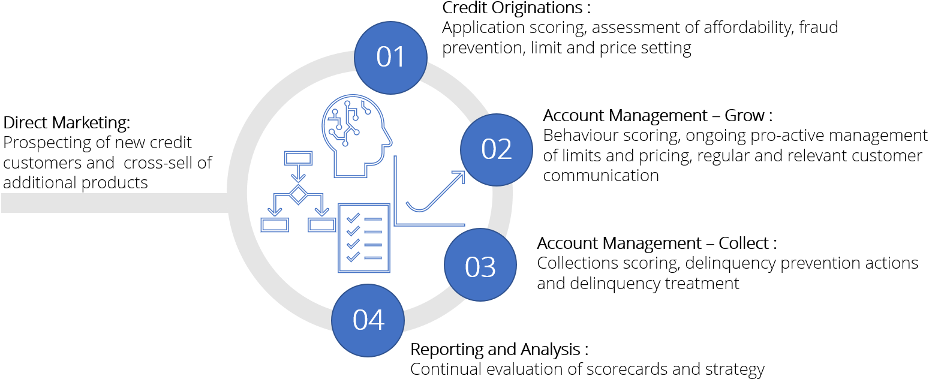
Ideally, decisioning tools should be not only be consistent across the entire life cycle, but also flexible enough to manage the nuances of data and decisioning requirements at each life cycle point. The decision engine sits at the centre of the credit function and draws in all data and analytics sources, to operationalise the outcomes of scorecard developments, rule assessments, credit strategy designs, and then feeding data into performance analysis.
This does not discount the importance of data analytics and the data analytics platform. It is in data analytics that data is aggregated and analysed, and new models are developed. Analytics allows for the conceptualisation of new strategies, while decisioning ensures their successful testing and execution.
Whilst the power of the decision engine can be used to aggregate and compute all the variables necessary for decisioning, it is not recommended to place all of the calculations in the actual decision point runtime, in order to avoid performance issues and ensure rapid responses.
Static data aggregations are best left to the analytical platform, whilst dynamic data remains in the decision engine, where parameters can be tested against one another.
In organisations where machine learning and AI models have come to the fore, the decision engine needs to be able to consume frequently retrained models with a minimum of integration effort. Ideally, machine learning models should remain in their own environment, and the decision engine should have flexible API endpoints available to request and retrieve the latest model outcomes for each customer or applicant.
Using this methodology, minimal model deployments (and subsequent integration testing) are required. When models are being retrained or refreshed as frequently as monthly, implementing, and testing these integrations within a decision engine will require a great deal of effort. This effort that can be better spent developing, deploying, and monitoring champion/challenger strategies that make use of the model outcomes.
These tasks can operate in parallel, as a better performing model will add value equally to both the champion and challenger strategies (if the scaling of the scores does not change), ensuring that testing is not interrupted every time a new model is deployed.
The second key requirement of the decision engine is its ability to integrate directly with the data that is used for model creation and training. Increases in the performance of data lakes and controlled access to these sources of data mean that it is now possible for the decision engine to use, in real-time, the same data sources that are used in analytics and model development.
If the data lake has been well structured, characteristic generation can be housed within the data lake, removing the need for characteristics to be generated in multiple environments e.g., the modelling system and the decision engine.
By having a single version of the model characteristics available to both decisioning and the development tool, then there is no need for time consuming data validations, which consume resources and delay the implementation of new models.
Modern credit decisioning requires data from a multitude of various sources. The decision engine becomes the custodian of these data retrieval processes, using APIs to integrate with internal and external data repositories, bringing the data into a central point for decisioning as and when it is required.
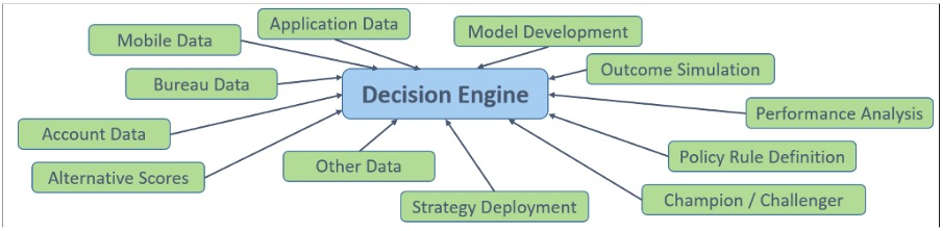
Once decisioning is complete, the decision engine can send all of the data and decisioning outcomes to the data lake, to enhance the reporting and analytics capabilities of the business.
The decision engine sits at the centre of a wide web of data sources and analytics platforms, bringing those insights into a centralised platform, from where the credit risk team can construct automated decisioning processes and strategies to continually enhance the value of business decisions
To add the most value to the organisation, the chosen decision engine should offer the following functionality and features, as a bare minimum:
- A user-friendly front end for the configuration of scorecards (or retrieval of scores from the machine learning modules), rule sets and strategy components. This front end should be consistent across all use cases, ensuring that the credit risk manager can easily move from one decisioning point to another (e.g., originations, collections, account management) without having to learn new tools or methodologies.
- The ability to cater for multiple products and segments within a single decisioning product.
- A system designed to support champion/challenger strategy testing. The system be able to assign a random number(s) to each application or account to ensure that that unbiased champion/challenger strategies can be allocated to specific percentages of applications/accounts.
- The assigned strategy should be clearly identifiable on the account/application, allowing strategies to be easily monitored and compared side-by-side, to identify which delivers the best performance. This creates an environment of continual improvement of strategies, always matched against business objectives.
- The ability to use historic data to simulate actions taken in new strategies. This functionality allows the business user to validate the operational impact of new strategies before deploying them. In turn, this mitigates the risk of deploying new strategies into production, by setting the expectations of what will result from the new strategies.
- All decisioning data should be written back to the data analytics platform, ensuring that these outcomes can be used in future learnings, scorecard developments and analytically driven strategy designs.
- Strategy deployment should be in the hands of the business users, without any IT intervention required. The system should ideally have built-in version creation and the ability to rollback to any previous configuration, ensuring that strategic mistakes can not only be avoided, but also reversed very quickly should the need arise.
- At the very least, a full audit trail should be retained for configuration amendments.
- Industry standard user security, access rights management and roles should be available. Decision engines are accessed by multiple members of the credit team. Each of these individuals should have secure logins, and roles should be assigned to ensure that they have access only to the areas of the system that they are responsible for.
Modern decision engines offer a significant variety of functionality, with vendors focusing on the functionality that is unique (or at least strongly presented) within their systems to woo potential buyers. The market is saturated, with many providers offering decisioning capability.
While this may appear to be to the advantage of the buyer (more choice can only be a good thing), it does place greater requirements on the purchaser to ensure that the system that they choose meets all of their current and future requirements.
While well-appointed and easy to use decision engines can add immense value to the organisation employing them, the opposite is also true. If the software is difficult to use, or overly complex in accessibility, it can result in slowing down business change, and ultimately cost the organisation time, money and flexibility.
Be thorough in the assessment of a potential decisioning solution. Look for the key requirements that your business needs, and never be swayed by the various bells and whistles which vendors will try to attract your attention with. Some decision engine integration projects can be both costly and lengthy. Do not get to the end of the process only to realise that you have chosen the wrong tool.
About the Author
Jarrod McElhinney is a Client Solutions Manager at ADEPT Decisions.
About ADEPT Decisions
We disrupt the status quo in the lending industry by providing lenders with customer decisioning, credit risk consulting and advanced analytics to level the playing field, promote financial inclusion and support a new generation of financial products.